GP-GPU 구조 시리즈: 챕터 1 - Introduction
초창기 GPU는 비디오 게임의 실시간 렌더링을 담당하기 위해 개발되었다. 하지만 근 몇 년 사이에 GPU는 General-Purpose의 기능이 강해지면서, 다양한 연산들을 가속하기 위해 사용되었다. 그래서 GPU는 GP-GPU (General-Purpose Graphics Processing Unit)이란 이름이 붙게 되었다.
GP-GPU를 이용하면, 엄청난 양의 데이터를 병렬로 처리가 가능하기 때문에 머신러닝 연산에 사용이 됐고, 덕분에 엄청난 관심을 끌게 되었다. GP-GPU는 머신러닝 어플리케이션 외에도 데이터 간의 의존성이 없고, 데이터 플로우 역시 단순하다면 엄청난 병렬 처리 성능을 활용해 압도적인 속도로 연산이 가능하다.
다른 이야기이긴 하지만, CPU와 GPU와 같은 General-Purpose processor의 한계(energy, frequency, heat 등)가 뚜렷해지고 있기 때문에 NPU, TPU와 같은 특정 어플리케이션만을 타겟으로 하는 가속기들의 연구도 활발히 이루어지고 있다.
Brief History of GPUs
컴퓨터 그래픽은 1960년대, 아이번 서덜랜드의 프로젝트였던 스케치패드에서 시작됐다. 당시 컴퓨터 그래픽은 영화나 애니메이션의 그래픽의 렌더링에 사용됐고, 그와 동시에 비디오 게임 등에 사용하기 위해 실시간 렌더링 역시 연구가 진행되고 있었다. 초창기 그래픽 카드는 1981년도의 IBM Monochrome Display Adapter (MDA)에서 시작됐다. IBM MDA는 텍스트 렌더링 용도로만 사용됐지만, 이후 그래픽 카드는 2D와 3D 그래픽의 연산 가속을 위해 발전했다.
NVIDIA GeForce 256과 같은 초창기 3D 그래픽 카드는 상당부분 fixed-fucntion을 가속하기 위해 사용됐다. 이후 NVIDIA는 2001년, GeForce 3에 vertex shader와 pixel shader와 같은 프로그래밍이 가능한 하드웨어를 추가해 3D 그래픽 연산을 좀 더 자유롭게 만들었다. Vertex shader와 pixel shader의 텍스쳐와 쉐이더 부분을 행렬로 바꿔치기 한다면 선형대수 연산이 가능했기 때문에, 학계에서는 이를 이용해 다양한 연산들을 가속했다.
이런 노력들이 빛을 발했는지, GPU 회사들은 GPU를 다목적 (General-Purpose) 프로그래밍을 지원해줬으며, NVIDIA GeForce 8 시리즈가 최초의 상업용 GP-GPU로 출시됐다. GeForce 8 시리즈에는 다목적 프로그래밍의 성능을 높이기 위해 기존에는 없었던 많은 기능들이 추가됐는데, 가장 대표적인 예시로 scratchpad 메모리, 다양한 메모리 주소 공간 등이 있다.
이를 필두로, atomic 함수, double-precision 연산, 3D grid, dynamic parallelism 등 프로그래밍을 위한 기능들이 점차 추가됐다. 현재는 다양한 연산을 위한 라이브러리 (cuBLAS, cuDNN, cuFFT 등)를 제공하며, TensorCore와 같은 하드웨어가 추가되어 편의성과 성능 모두 엄청나게 향상되었다.
GPU Hardware Basics
GPU와 CPU의 관계
기본적으로 GPU는 스스로 동작하는 하드웨어가 아니다. 가속기의 개념으로 사용이 되는 하드웨어이기 때문에 CPU의 제어가 필요하다. CPU와 GPU의 역할이 나뉘어진 이유 중 하나로, 연산 가속의 처음과 끝에는 I/O 디바이스의 접근이 필요하기 때문이다. 이외에도 효과적인 GPU 연산 가속을 위해서 다양한 작업들이 필요하다. 그렇기 때문에 GPU 제조회사들은 CPU가 GPU를 효과적으로 제어할 수 있도록 여러 API를 제공한다.
GPU 컴퓨팅 시스템
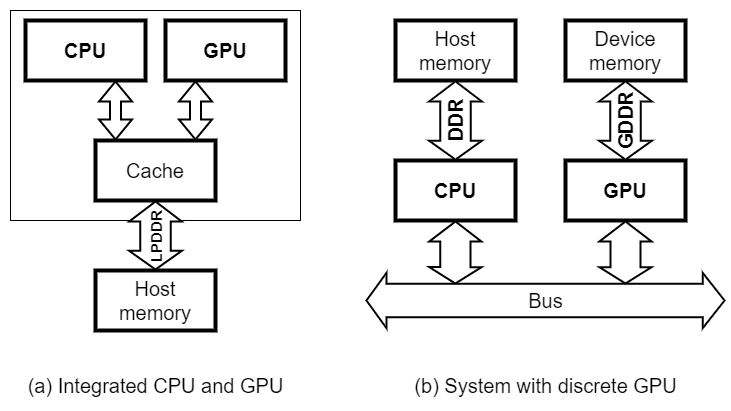
아래 그림은 CPU와 GPU가 포함된 일반적인 컴퓨터 시스템의 블록 다이어그램이다.
 |
|---|
| Figure 1. CPU가 포함된 GPU 컴퓨팅 시스템 분류 |
Figure 1.은 CPU와 GPU가 함께 존재하는 컴퓨팅 시스템을 분류한 그림이다. 그림과 같이, 크게 두 가지로 분류가 가능하다. 좌측(a)과 같은 구조는 휴대폰과 같은 모바일 시스템에서 찾아볼 수 있고, 우측(b)과 같은 구조는 PC나 서버와 같은 시스템에서 찾아볼 수가 있다.
Integrated GPU
좌측(a)의 구조를 integrated GPU라 부른다. 여기서는 CPU와 GPU가 하나의 DRAM 메모리 공간을 공유한다. 그런 이유로, 둘은 동일한 메모리 인터페이스를 사용할 수 밖에 없다. Integrated GPU는 위에서 언급한 바와 같이 모바일 시스템에서 주로 찾아볼 수 있기 때문에 저전력이 중요하다. 그래서 대부분의 integrated GPU는 전력 소모가 적은 LPDDR 메모리를 사용한다.
Discrete GPU
우측(b)의 구조를 discrete GPU라 부르는데, 여기서는 CPU의 메모리와 GPU의 메모리가 분리되어 있다. 일반적으로 CPU의 메모리는 host memory 또는 system memory라 부르고, GPU의 메모리는 device memory라 부른다.
리눅스 기반 시스템에서 NVIDIA GPU를 사용할 때, $ nvidia-smi 커맨드를 입력하면 아래와 같은 출력을 얻을 수가 있다.
여기서 나타나는 메모리 용량이 각 GPU의 device memory 용량을 의미한다.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.86 Driver Version: 470.86 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| 30% 26C P8 22W / 350W | 1MiB / 24268MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| ... | ... | ... |
+-------------------------------+----------------------+----------------------+
| 5 NVIDIA GeForce ... On | 00000000:E1:00.0 Off | N/A |
| 30% 24C P8 10W / 350W | 1MiB / 24268MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Discrete GPU 구조에서는 CPU와 GPU가 서로 다른 DRAM technology를 사용하기 때문에, 각 프로세서에 좀 더 특화된 메모리 인터페이스를 사용한다. CPU의 경우 bandwidth보다는 latency가 더 중요하기 때문에 DDR을 사용하며, GPU의 경우 latency보다 bandwidth가 더 중요하기 때문에 GDDR을 사용한다. GPU가 bandwidth를 중요시하는 이유는 GPU의 내부 구조에 대해서 이야기하면서 자세히 설명하도록 하겠다.
GPU의 동작 플로우
위에서 언급했다시피, GPU는 CPU의 도움을 받아야 효과적으로 프로그램을 구동할 수 있다. 일반적으로 GPU 프로그램이 구동하는 플로우를 살펴보자.
어플리케이션은 CPU를 이용해 동작하는 부분과 GPU를 이용해 동작하는 부분으로 나뉜다.
 |
|---|
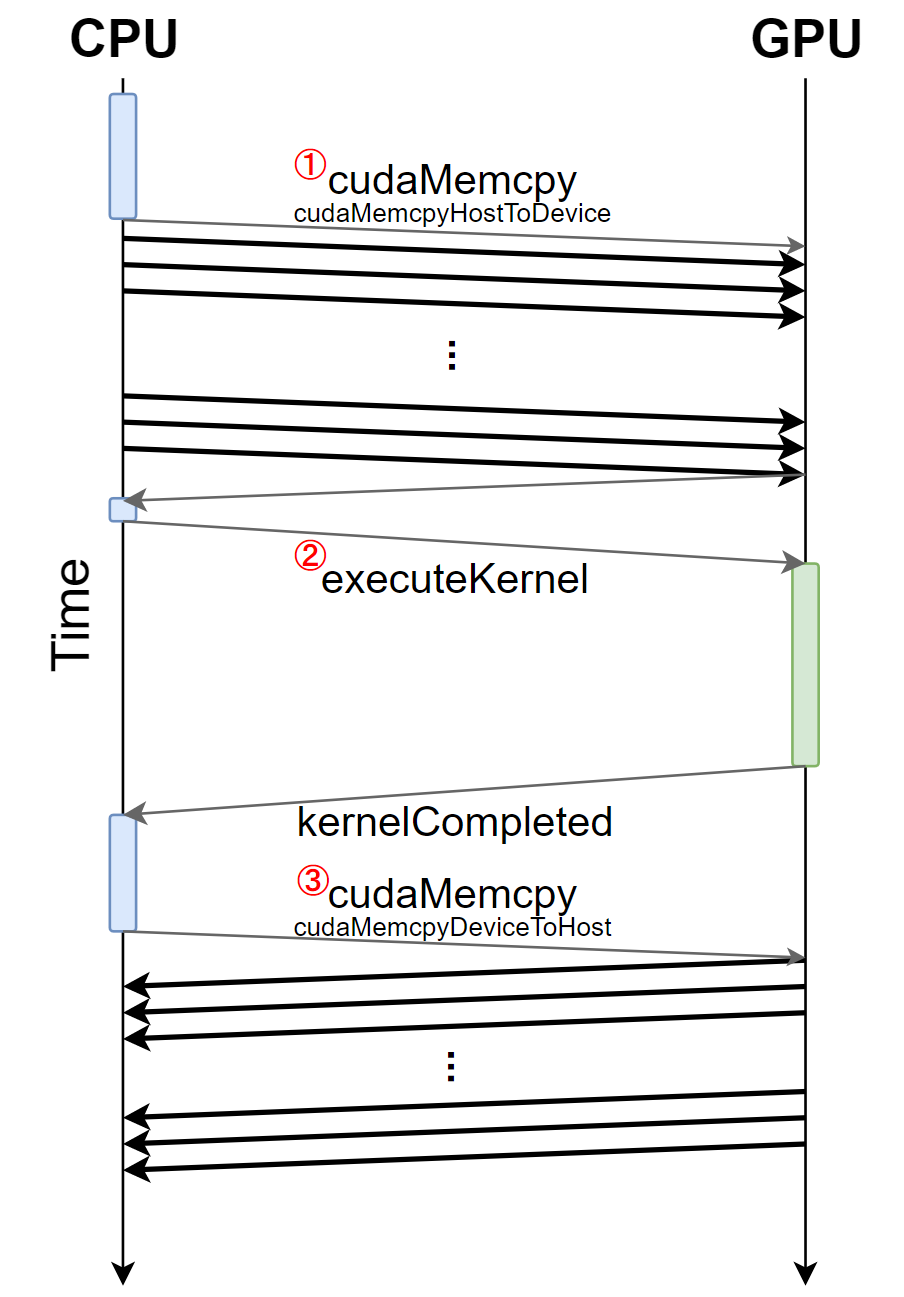
| Figure 2. 커널의 동작 과정. |
Figure 2.는 GPU 프로그램의 동작 단위인 커널의 구동 과정을 보여준다. 동작을 자세히 살펴보도록 하겠다.
- 먼저 CPU를 이용해 어플리케이션을 구동하다가, CPU는 API를 이용해 GPU에서 구동할 데이터들을 차례차례 host memory에서 device memory로 옮긴다.
- 모든 데이터들이 다 옮겨졌으면 GPU 연산이 정의된 함수인 커널이 호출되고, GPU는 커널에 정의된 대로 device memory 내의 데이터들을 연산한다.
- 연산이 끝났으면 커널이 종료되고 CPU는 다시 API를 이용해 연산이 끝난 데이터를 device memory에서 host memory로 옮긴다.
위와 같은 방식이 가장 일반적이지만, 프로그래머가 직접 GPU 연산을 수행할 데이터를 옮겨줘야하기 때문에, 이러한 번거로움을 덜고자 NVIDIA의 Pascal 마이크로아키텍처부터는 Unified memory란 것을 지원한다. Unified memory에서는 CPU와 GPU가 동일한 가상 메모리 주소 공간을 사용하기 때문에 프로그래머가 직접 데이터를 옮기지 않아도 된다. 하지만 Unified memory를 사용하게 되면 프로그램이 동작하는 동안, device memory에 존재하지 않는 데이터를 필요한 때에 가져오기 때문에 성능 저하가 존재한다.
GPU 내부 구조
현대의 GPU는 수 많은 코어로 이루어져있다. NVIDIA는 이러한 코어들을 Streaming Multiprocessor (SM)라고 부르고, AMD는 이를 Compute Unit이라 부른다.
각 코어는 Single-Instruction Multiple-Thread (SIMT) 방식으로 프로그램을 실행한다. 이는 Flynn’s taxonomy의 Single-Instruction Multiple-Data (SIMD)와 유사한 방식이지만, 데이터에 초점을 맞춘 SIMD와 달리, SIMT는 쓰레드에 초점을 두고 있다.
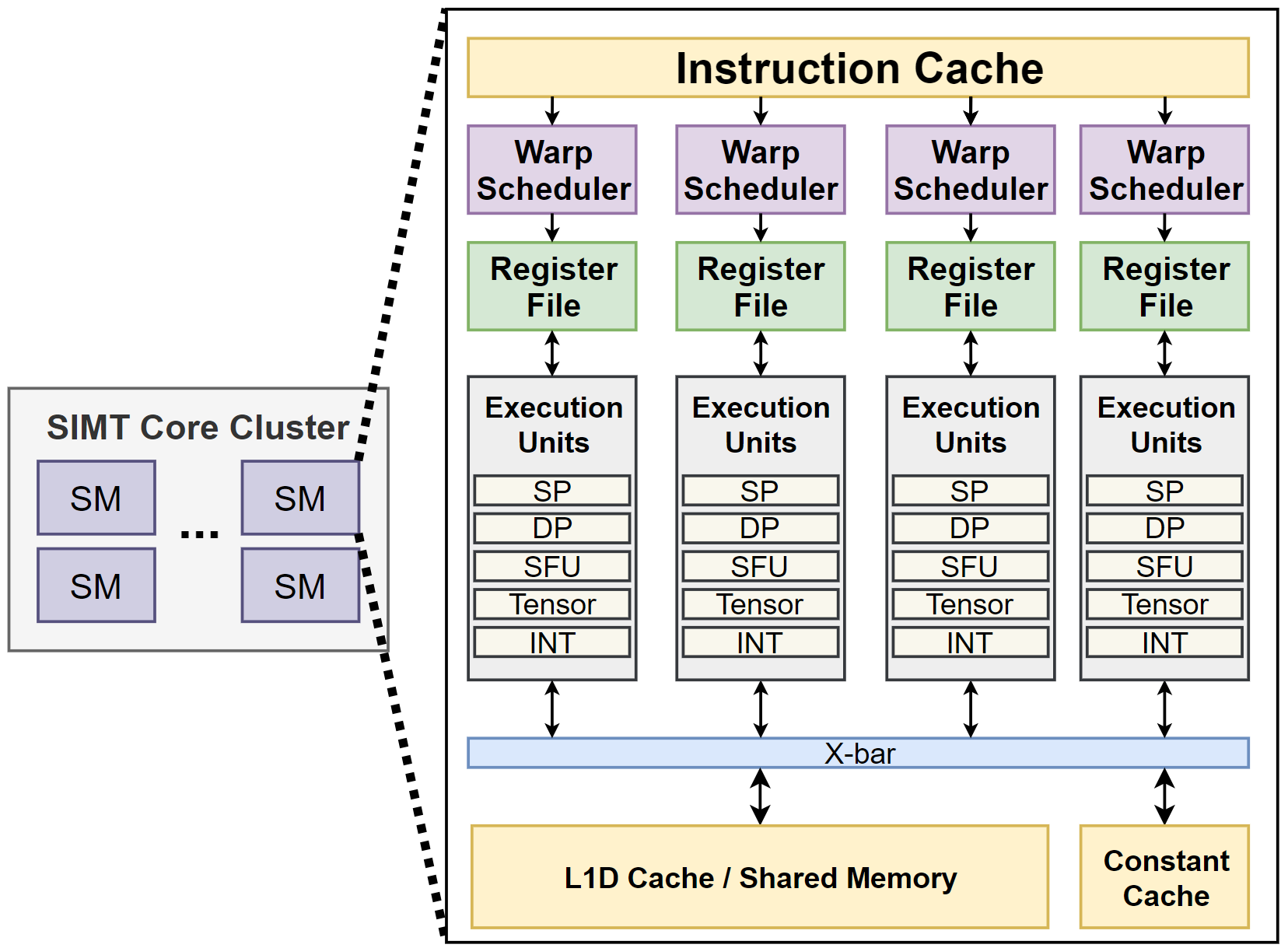
GPU는 수 천개의 쓰레드를 구동하며, 동일한 SM 내의 쓰레드들은 scratchpad memory를 통해 통신한다. 또한 barrier operation이 있어, 이를 가지고 synchronization을 한다. 각 SM은 L1-Insturction/Data cache를 갖고 있는 덕분에, 하위 계층 메모리 시스템(L2 cache, DRAM 등)으로 오고가는 메모리 트래픽의 양이 줄어 코어에 공급되는 데이터 양을 어느정도 유지할 수 있다. 또한 많은 양의 쓰레드가 SM 내에서 연산을 하고 있기 때문에, 하위 계층 메모리를 접근하면서 생기는 access latency는 어느정도 숨겨지게 된다. 이런 현상을 latency hiding이라 하는데, latency hiding 덕분에 GPU는 latency보다 bandwidth가 성능을 결정짓는 중요한 요인이 되었다.
 |
 |
|---|---|
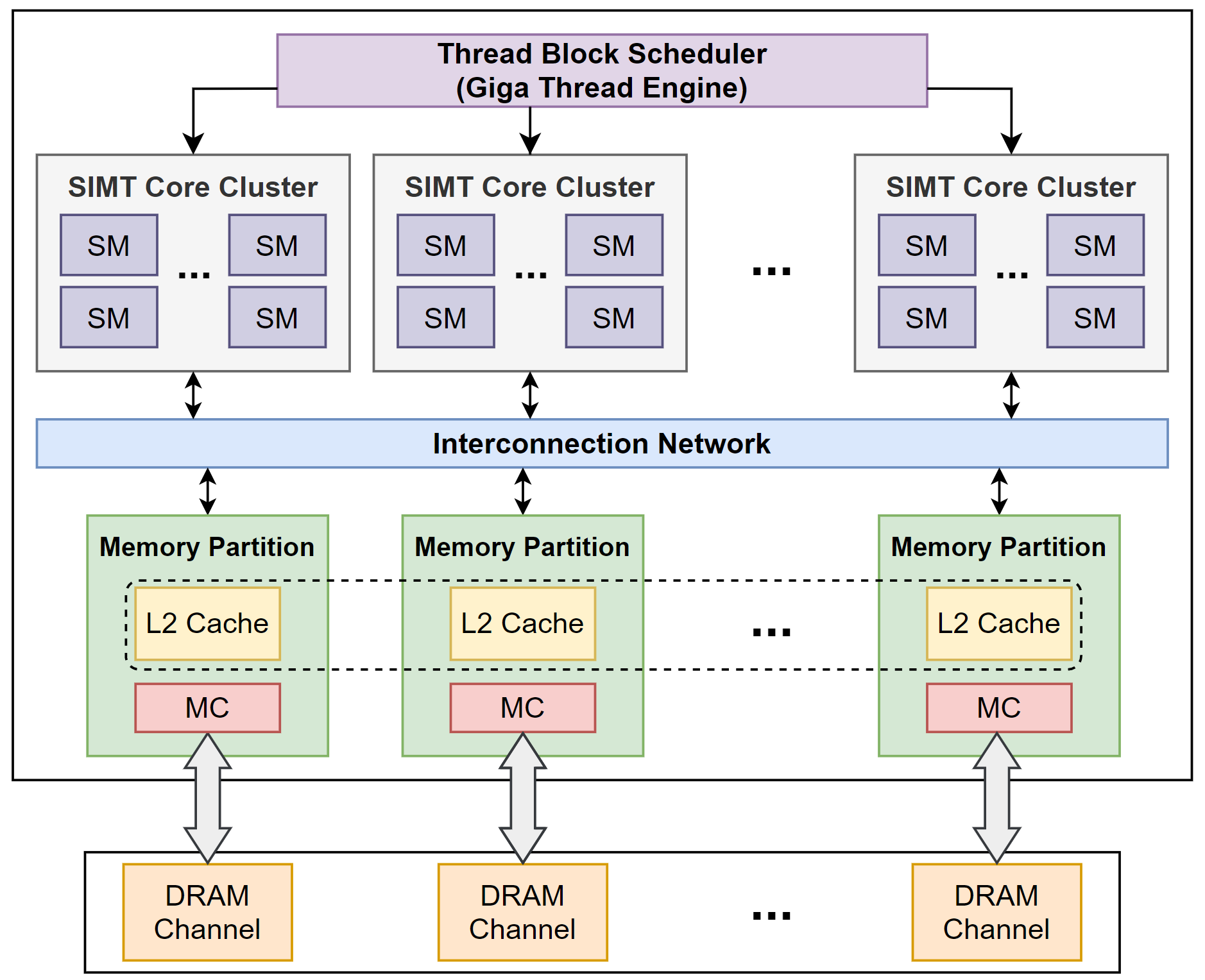
| Figure 3-1. NVIDIA GPU의 내부 구조. | Figure 3-2. NVIDIA GPU의 SM 내부 구조. |
Figure 3.은 GPU 중에서도 가장 점유율이 높은 NVIDIA의 GPU 구조를 간단히 표시한 다이어그램이다. 그림의 좌측(Figure 3-1.)은 GPU 내부를 전반적으로 나타냈고, 그림의 우측(Figure 3-2.)은 그 중에서도 SM만을 나타냈다.
GPU의 메모리 시스템
좌측 그림을 통해 알 수 있듯, GPU는 높은 computational throughput을 제공하기 위해, 많은 수의 SM이 탑재되어 있다. 높은 computational throughput에 맞게 많은 데이터를 공급해야하기 때문에 메모리 시스템도 마찬가지로, 높은 수준의 병렬 접근이 가능하도록 설계되어 있다. 그리고 높은 수준의 병렬 접근이 가능하도록, GPU의 메모리 시스템은 다수의 메모리 채널로 구성되어 있으며, 각 채널은 LLC의 각 bank와 함께 memory partition이란 단위로 묶인다.
각각의 memory partition은 on-chip interconnection network를 통해 SM들과 연결되어 있어, 모든 SM들은 L2 캐시와 DRAM의 모든 데이터를 접근할 수 있다.
GPU의 연산 코어
CUDA 프로그램에서 쓰레드는 소프트웨어 적으로는 thread block이란 단위로 묶이지만, 하드웨어 적으로는 warp란 단위로 묶이게 된다. 따라서 thread block에 할당된 쓰레드들을 warp 단위로 변환해, 각 SM으로 스케쥴링하는 하드웨어가 Thread Block Scheduler이다. 할당된 warp들은 SM 내에서 또다시 Warp Scheduler에 의해 스케쥴링 되어 실제 연산을 시작하게 된다.
정리
이번 글에서는 GPU의 역사와 특징, 구조를 간략하게 다뤄봤다. 이후 챕터들에서 GPU 프로그래밍 모델과 하드웨어 구조를 자세히 다룰 예정이다. 현재까지 나온 용어들 중, 아직 설명하지 않은 용어들도 추후에 설명하도록 할 것이다.
참고자료
- T. M. Aamodt, W. W. L. Fung, and T. G. Rogers, General-purpose graphics processor architectures. San Rafael, California: Morgan & Claypool Publishers, 2018. doi: 10.2200/S00848ED1V01Y201804CAC044.
- M. Khairy, J. Akshay, T. Aamodt, and T. G. Rogers, “Exploring Modern GPU Memory System Design Challenges through Accurate Modeling,” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pp. 473–486, May 2020, doi: 10.1109/ISCA45697.2020.00047.
- [GPGPU Series 3] GPU Architecture Overview – MKBlog
Leave a comment