GP-GPU 구조 시리즈: 챕터 3-1 - The SIMT Core: Instruction and Register Data Flow
현대의 GP-GPU는 수천~수만개의 쓰레드를 동시에 처리할 수 있다. 이를 가능케하기 위해 SIMT 코어는 다양한 방법을 채용했는데, 이번 게시글에서는 이를 알아보도록 하겠다.
 |
|---|
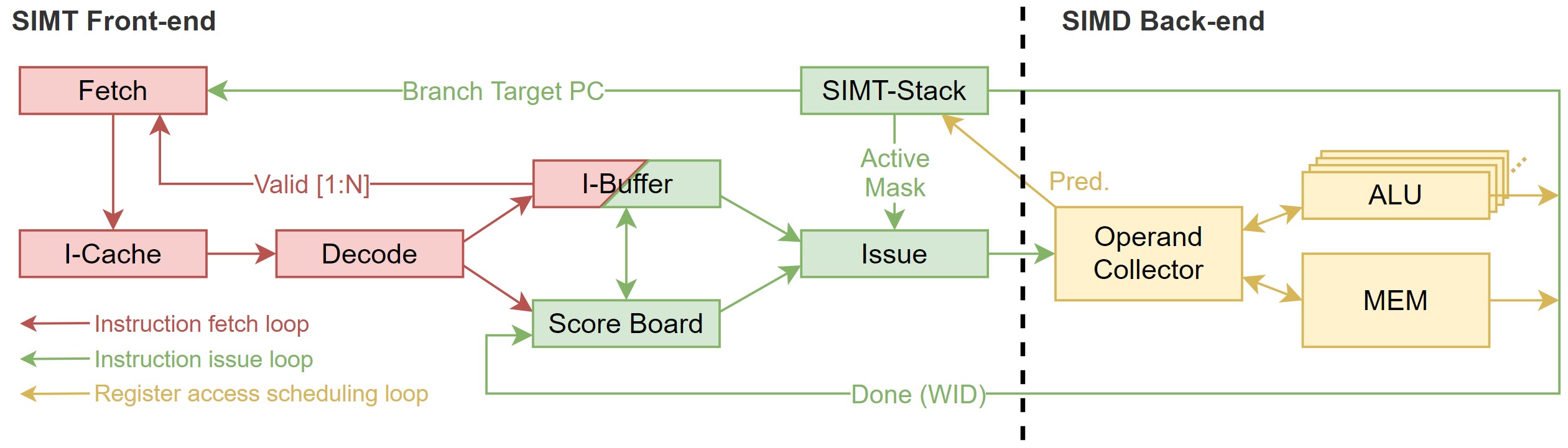
| Figure 1. GPU 마이크로아키텍처의 파이프라인 |
Figure 1.과 같이, GPU 마이크로아키텍쳐의 파이프라인은 SIMT front-end와 SIMD back-end로 나뉜다. 파이프라인은 크게 3개의 스케쥴링 루프를 갖고 있다. 각 루프는 instruction fetch loop, instruction issue loop, register access scheduling loop라 부르는데, 루프들은, 아래와 같이, 파이프라인의 스테이지들을 포함한다.
- Instruction fetch loop: Fetch, I-Cache, Decode, I-Buffer
- Instruction issue loop: I-Buffer, Scoreboard, Issue, SIMT stack
- Register access scheduling loop: Operand Collector, ALU, Memory
지금부터는 파이프라인의 각 스테이지들이 어떤 역할을 하는지 자세히 살펴볼 것이다. N-Loop approximation이란 방법을 이용해, GPU의 동작을 설명할 것이다. One-loop approximation에선, 최대한 단순화하여 GPU 파이프라인을 설명한 뒤, two, three-loop으로 가면서 세세한 부분을 설명할 예정이다.
One-Loop Approximation
먼저 다른 건 제쳐두고, 단일 스케쥴러를 가진 GPU를 가정해보자. CUDA 프로그래밍 모델 매뉴얼과 차이가 있을 수는 있지만, 이해를 돕기 위해 많은 부분을 생략하고 설명할 예정이다.
먼저, 스케쥴링의 단위는 warp이다. 매 사이클마다 하드웨어는 warp를 선택해 스케쥴링한다. 이때 warp의 program counter를 이용해 instruction memory에서 warp가 실행할 다음 instruction을 접근한다. Instruction fetch가 끝나면, decode 단계를 거친 뒤, register file에서 source operand register를 불러오게 된다. register file에서 reigster를 불러오면서, 병렬적으로, SIMT execution mask가 결정된다.
Execution mask와 source register가 모두 준비가 완료되면, SIMD 방식으로 연산이 시작된다. 이때, SIMT execution mask를 바탕으로 실행해도 되는 lane이 결정되며, 그 lane에 해당하는 쓰레드만 실행되게 된다. GPU의 function units은 CPU와 마찬가지로 heterogeneous하다. 즉, function unit은 instruction의 일부1만 처리하게 된다.
모든 function unit은 내부에 lane을 갖고 있는데, 이 lane은 SIMT로 처리할 수 있는 쓰레드의 수만큼 존재한다. 예를 들어, NVIDIA의 warp는 32개의 쓰레드로 구성되어 있기에, 각 function unit은 총 32개의 lane을 갖고 있다.
SIMT Execution Masking
CUDA 프로그램은 SIMT execution model이 있기 때문에, 프로그래머는 개별 쓰레드를 다루는 MIMD의 방식으로 프로그래밍이 가능하다. 이를 위해선 기존의 predication 만으로도 충분하지만, GPU의 SIMT execution model은 기존의 predication과 더불어, predicate mask stack (SIMT stack)을 함께 이용한다.
CPU에서는 predication을 위해 다수의 predicate register를 사용한다. 하지만 GPU에서 predicate register를 이용하면, 많은 수의 쓰레드를 감당할 수 없어, 하드웨어 오버헤드가 기하급수적으로 커진다. 따라서 SIMT stack을 이용해 하드웨어 오버헤드를 줄였다.
SIMT stack을 사용하면 두 가지 이슈를 간단히 해결할 수 있다.
- Nested control flow: 하나의 브랜치가 다른 브랜치에 의존적인 경우. 이는 올바른 functionality를 위해 필수적이다.
- Skipping computation entirely: Warp 내의 모든 쓰레드가 control flow path에 속하지 않는 경우. 이는 성능 향상에 큰 도움이 된다.
실제 SIMT stack에서는 특수한 instruction을 이용해 관리되지만, 이번 글에서는 하드웨어만으로 관리되는 SIMT stack을 소개하고자 한다.
아래의 첫 번째 코드는 do-while loop 안에 두 개의 nested branch로 이루어진 CUDA C 코드이다. 두 번째 코드는 CUDA C코드를 컴파일해서 PTX Assembly로 만든 것이다.
do {
t1 = tid * N; // A
t2 = t1 + i;
t3 = data1[t2];
t4 = 0;
if ( t3 != t4 ) {
t5 = data2[t2]; // B
if ( t5 != t4 ) {
x += 1; // C
} else {
y += 2; // D
}
} else {
z += 3; // F
}
i++; // G
} while ( i < N );
A: mul.lo.u32 t1, tid, N;
add.u32 t2, t1, i;
ld.global.u32 t3, [t2];
mov.u32 t4, 0;
setp.eq.u32 p1, t3, t4;
@p1 bra F;
B: ld.global.u32 t5, [t2];
setp.eq.u32 p2, t5, t4;
@p2 bra D;
C: add.u32 x, x, 1;
bra E;
D: add.u32 y, y, 2;
E: bra G;
F: add.u32 z, z, 3;
G: add.u32 i, i, 1;
setp.le.u32 p3, i, N;
@p3 bra A;
 |
|---|
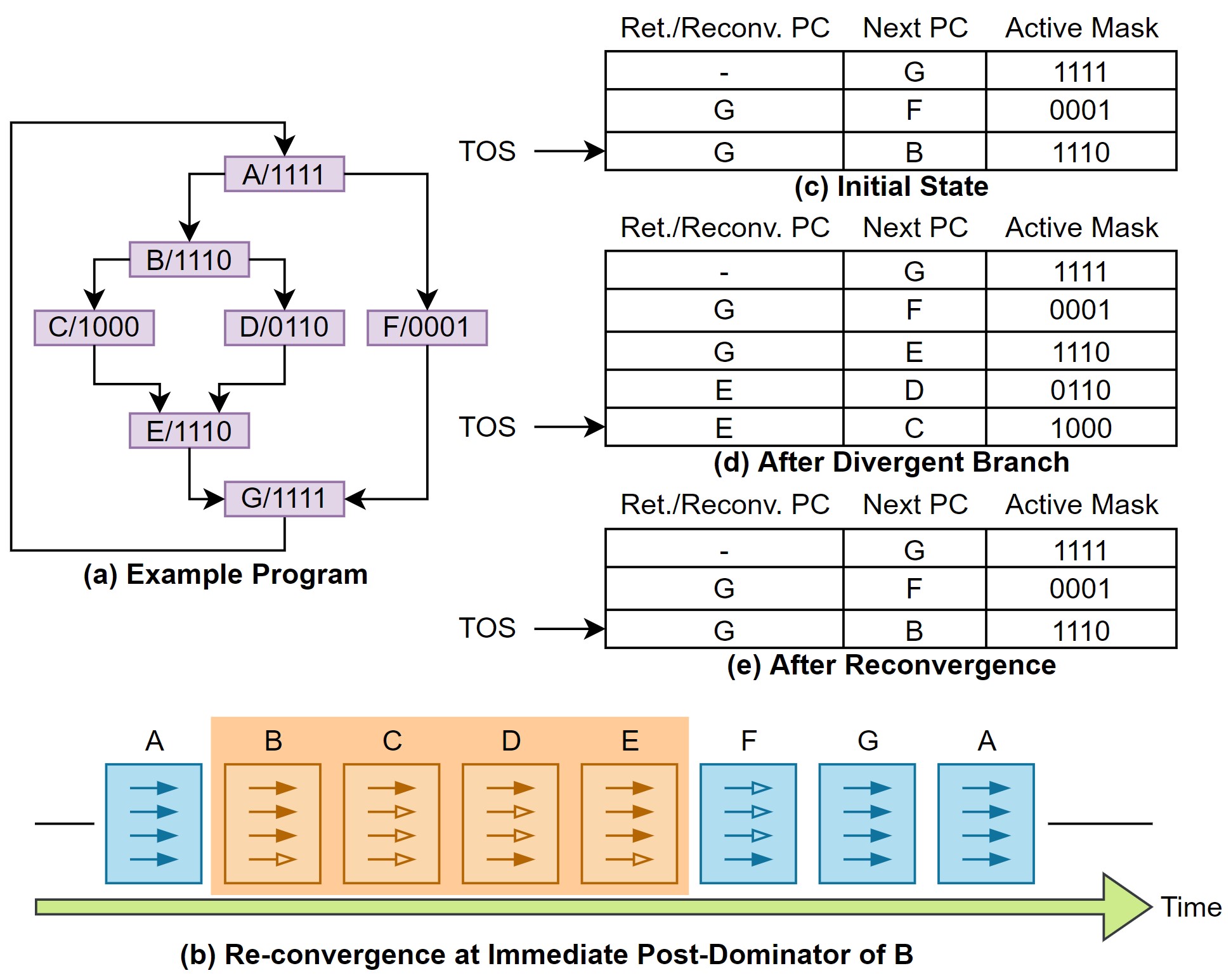
| Figure 2. CUDA C 코드 예시에 해당하는 SIMT Stack 동작 |
이 코드를 SIMT stack의 동작과 비교하면 Figure 2.와 같다. 그림 예시에서는 한 warp의 쓰레드 개수는 4개라고 가정한다.
- (a)는 CUDA C 코드의 branch들의 control flow를 의미한다. 그림 내의 각 블록의 알파벳은 CUDA C 코드의 알파벳과 동일한데, branch divergence가 일어난 뒤 실행되는 부분이라고 보면 된다.
- (c~e)는 SIMT stack이 divergence를 거치면서 어떻게 변하는지 나타낸 그림이다. Branch들이 합쳐지는 Return/Reconvergen 포인트를 의미하는 Ret./Reconv. PC는 분기된 branch들이 합쳐지는 위치를 나타낸다. Next PC는 warp의 다음 program counter를 나타내며, 곧 실행될 블록이다. Active mask는 해당 블록에서 어떠한 쓰레드 (branch의 control flow에 속하는)만 동작할 것인지를 나타내는 블록이다. TOS는 top of stack의 줄임말로 현재 stack의 맨 위를 나타내는 포인터이다.
- (b)는 SIMT stack에 따라 실제 warp 내의 쓰레드들이 동작하는 과정을 시간 순으로 나타낸 그림이다. 비어있는 화살표는 동작하지 않는 쓰레드를 의미하며, 색칠 된 화살표는 동작하고 있는 쓰레드를 의미한다. SM 코어는 SIMT 방식으로 동작하기 때문에, 분기를 만나더라도 warp 내의 쓰레드는 모두 하나의 function unit에 들어가 동작하게 된다. 즉, 실제로는 warp는 instruction에 따라 sequential하게 실행되는데, active mask란 개념을 도입해 쓰레드 연산 결과를 저장하지 않음으로 분기를 구현했다.
이를 바탕으로 그림을 자세히 따라가보자.
일단 (a)의 그림을 살펴보면, 블록 A에서는 어떠한 divergence도 일어나지 않기 때문에 warp 내의 모든 쓰레드가 동작한다 (active mask = 1111). 이후 B와 F 블록으로 branch divergence가 발생하게 된다. Branch divergence가 일어나기 전에, 그림 (c)와 같이 PC 값들이 SIMT stack이 쌓이게 된다. SIMT stack에는 각 branch의 다음 PC를 가리키는 스택들이 쌓이게 되며, 이에 해당하는 active mask가 스택에 함께 저장된다. 각 스택에는 reconvergent 블록에 해당하는 PC 정보가 함께 저장되며, 이를 이용해 control flow의 functionality를 보장한다. SIMT stack의 가장 위는 B를 next PC로 가리키고 있기 때문에, B 블록을 먼저 실행한다. B의 active mask는 1110으로 warp 내의 3개의 쓰레드만 branch에 해당하기 때문에, 해당 쓰레드의 연산만 유효하다.
SIMT stack을 쌓고 제거하는 과정을 반복하며, nested control flow를 처리한다. 그래서 GPU의 SM 코어는 복잡한 control flow도 functionality를 보장할 수 있다.
SIMT Deadlock and Stackless SIMT Architectures
하지만 SIMT stack을 이용한 control flow 처리는 몇 가지 문제점이 있다. 가장 큰 문제는 SIMT deadlock이라 부르는 현상이다. Volta 마이크로아키텍처 이전에는 SIMT deadlock을 해결하기 위해, 프로그래머가 직접 코드를 변경해야 했다. NVIDIA는 Volta 마이크로아키텍처부터, Independent Thread Scheduling이라 불리는, stackless 방식을 도입해 SIMT deadlock 문제를 해결했다. Independent thread scheduling을 설명하기 전에, SIMT deadlock에 대해 먼저 설명한 후, ITS에 대해서 얘기하도록 하겠다.
SIMT Deadlock
먼저 아래 코드를 살펴보자.
*mutex = 0; // A
while (!atomicCAS(mutex, 0, 1)); // B, B'
// some critical section // C
atomicExch (mutex, 0);
여기선 atomic operation으로 mutex를 조작해, 여러 쓰레드가 critical section을 접근하도록 만들었다.
 |
|---|
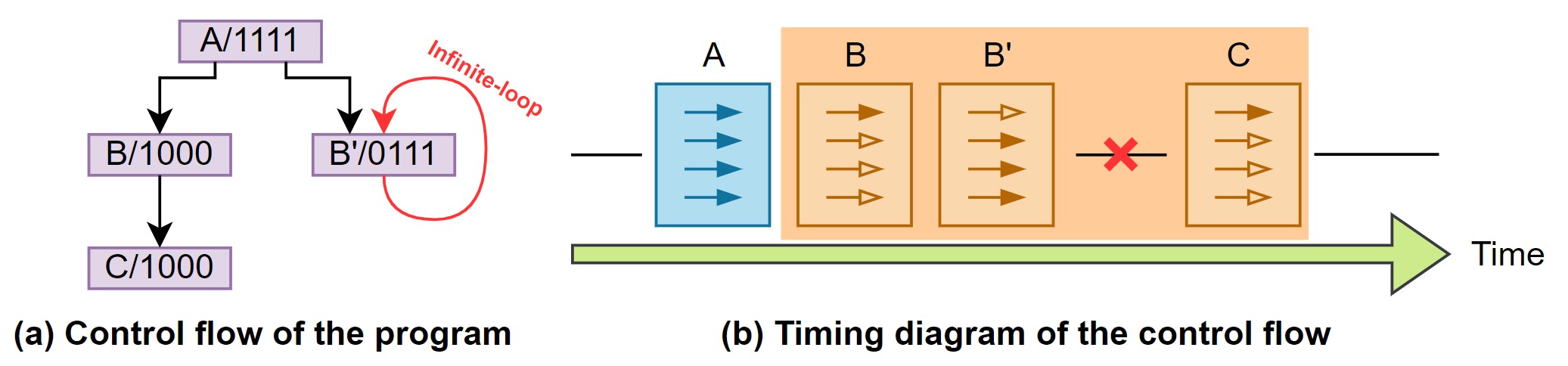
| Figure 3. SIMT deadlock 예시 |
Figure 3.의 동작을 시간에 따라 표현했다. SIMT Core에서 branch divergence가 일어나면 sequential 하게 동작한다는 것을 염두해두고 살펴보자.
모든 쓰레드는 mutex에 0을 대입한다 (A 블록). 그리고 while의 조건문에 들어가게 되면, branch divergence가 일어나게 된다.
첫 번째 쓰레드는 여기서 mutex를 잠그고 critical section에 들어간다 (B 블록).
다른 쓰레드들은 mutex가 해제되길 기다린다 (B’ 블록).
하지만 첫 번째 쓰레드가 atomicExch (mutex, 0) 구문에 도달해야 mutex는 해제된다 (C 블록).
C 블록은 B’ 블록이 끝나야 실행될 수 있는데, while 구문에서 mutex를 기다리며 무한 루프를 돌고 있기 때문에 실행될 수 없다.
이 때문에 SIMT deadlock이 발생한다. 이러한 현상을 SIMT deadlock 중에서도 spinlock이라 부른다.
SIMT deadlock은 spinlock을 제외하고도 다양한 경우에 발생한다.
done = false;
*mutex = 0;
while (!done) {
if (atomicCAS(mutex, 0, 1) == 0) {
// critical section
atomicExch (mutex, 0);
done = true;
}
}
기존에는 spinlock을 해결하기 위해, 기존 코드를 위처럼 수정해 문제를 해결했다. 프로그래머에게 추가적인 하드웨어 지식을 요구했다. 하지만 stackless 구조를 채용한 뒤로는 이런 번거로운 작업이 사라지게 됐다.
Stackless SIMT Architectures
Stackless SIMT 구조는 per-warp convergence barrier를 이용한다. Figure 4.는 NVIDIA 특허 문서에서 발췌한 내용이며, per-warp convergence barrier 동작에 필요한 필드들이다.
 |
|---|
| Figure 4. Stackless SIMT 동작을 위한 필드 |
-
Barrier Participation Mask: 주어진 warp에서 어떤 쓰레드가 convergence barrier에 속하는지를 나타낸다. Warp 내의 barrier participation mask는 1개 이상일 수 있다.
-
Barrier State: Barrier participation mask에 속한 쓰레드 중, 어떤 쓰레드가 convergence barrier에 도달했는지를 추적하기 위한 필드이다.
-
Thread State: Warp 내의 각 쓰레드가 현재 어떤 상태인지를 나타낸다. 쓰레드는 총 3가지의 상태를 가진다. 각 상태는 ready to execute, blocked, yielded가 있다.
-
Thread rPC: 대기 중(active 상태가 아닌)인 쓰레드의 다음 instruction의 주소를 저장한다.
-
Thread Active: Warp 내의 쓰레드 중 어느 쓰레드가 active 상태인지를 나타낸다. 각 쓰레드에 대해 1-bit 씩 필요하다.
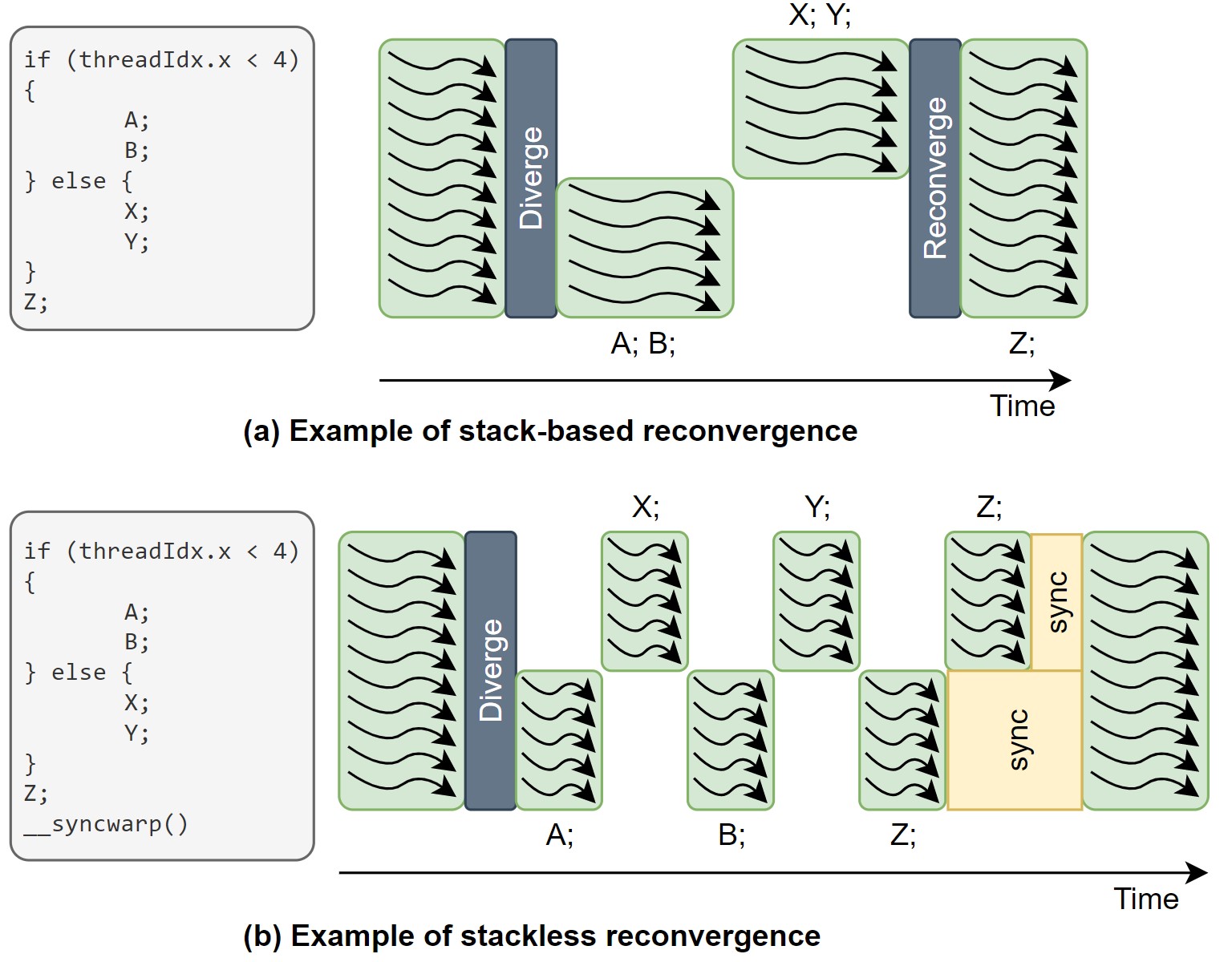
Stackless SIMT 구조는 stack-based SIMT와 달리, 스케쥴러가 분기들을 자유롭게 넘나들 수 있다. 그렇기 때문에 SIMT deadlock을 해결 가능하다. Figure 5.는 stack-based SIMT와 stackless SIMT의 예시를 보여주는데, 여기서 각각의 SIMT 구조가 어떤 식으로 동작하는지 확인할 수 있다.
 |
|---|
| Figure 5. Stack-based SIMT와 stackless SIMT의 동작 예시 |
Warp Scheduling
이해를 돕기 위해 여전히 GPU를 간단한 구조로 가정하고 있다. 이 구조에서는 각 warp는 하나의 instruction만을 issue해 스케쥴링할 것이다. 그리고 issue 된 instruction이 끝나기 전까지 또다른 instruction을 issue 하지 않는다. 추가로, 메모리 시스템 역시 이상적이라고 가정할 것이다. 따라서 memory request가 들어오면 무조건 일정한 시간 (fixed latency)가 지난 후2 응답하게 된다.
위 가정이 붙은 상황에서는, fine-grained multithreading 만으로도 memory access latency를 모두 숨길 수 있을 만큼 충분한 양의 warp를 동작할 수 있다. 이런 상황에서는 단순한 round-robin 정책만으로도 스케쥴링을 충분히 할 수 있다. 그리고 모든 연산 코어에 warp를 채워넣을 수 있기 때문에 underutilization이 발생하지 않을 수 있다. 하지만 많은 warp가 동작하는 만큼 레지스터 역시 필요하기 때문에, warp의 수를 단순히 늘리는 것은 하드웨어 면적 오버헤드가 커지게 된다.
실제 상황에서는 메모리 시스템이 이상적이지도 않고, 하드웨어 면적도 제한이 있기 때문에 위와 같이 warp를 스케쥴링 할 수 없다. 그래서 memory access의 locality에 따라 조금씩 다른 정책을 이용한다. Texture map과 같이 locality가 높은 경우라면 round-robin을 이용하면 충분한 효과를 얻을 수 있지만, locality가 낮다면 동일한 thread를 계속 스케쥴링하는 것이 더더욱 효과적일 수 있다.
정리
분량이 너무 길어져서 two-loop approximation 부터는 다음 게시글에 계속 진행하도록 하겠다.
참고 자료
- T. M. Aamodt, W. W. L. Fung, and T. G. Rogers, General-purpose graphics processor architectures. San Rafael, California: Morgan & Claypool Publishers, 2018. doi: 10.2200/S00848ED1V01Y201804CAC044.
Leave a comment