GP-GPU 구조 시리즈: 챕터 4-1 - Memory System
GPU는 많은 양의 데이터를 한 번에 처리한다. 코어의 높은 throughput에 버금가는 데이터를 전달해야할 의무가 있기 때문에, 큰 용량을 가지기보다는 넓은 bandwidth를 제공하는 방식으로 발전해왔다. 이번 챕터는 메모리 시스템에 관한 내용이다.
First-Level Memory Structures
GPU는 first-level 메모리 계층으로 다양한 하드웨어를 갖고 있다.
하나는 “shared memory”를 위한 scratch pad와 data cache가 하나의 메모리를 함께 사용하는 unified L1 data cache이다. 다른 하나는 그래픽 데이터만을 따로 저장하는 L1 texture cache이다.
이 섹션에서는 둘의 구조가 어떠한지, core pipeline과 어떤 식으로 상호작용하는지 알아볼 예정이다.
Scratch Pad and L1 Data Cache
먼저 scratch pad에 대해 간단히 설명하겠다.
CUDA 프로그래밍 모델에서 shared memory는 같은 block 내의 모든 thread가 접근 가능한 상대적으로 작고 빠른 메모리 영역이다. Shared memory 영역의 데이터는 scratch pad라고 하는 메모리에 저장된다.
NVIDIA 특허 자료에 따르면, scratch pad로 SRAM이 사용된다. 이때 SRAM은 lane마다 bank가 하나씩 있으며, 각 bank는 하나의 read port와 write port가 달려있다. 덕분에 각 thread는 모든 bank에 접근이 가능하다. 하지만 여러 thread가 같은 bank의 다른 위치를 접근하게 되면 bank conflict가 발생한다.
이제 L1 data cache를 알아보자.
L1 data cache는 global memory 주소 공간의 데이터를 저장하는 용도로 사용된다. 여기서 특정 warp 내의 모든 thread가 요구하는 데이터가 하나의 L1 data cache block에 모두 존재한다면 단일 request 만으로 모든 데이터를 접근할 수 있다. 이러한 접근을 coalesced access라 한다. 반대로 특정 warp 내의 모든 thread가 요구하는 데이터가 여러 L1 data cache block에 흩뿌려져 존재한다면 여러 request를 보내야 모든 데이터를 접근할 수 있다. 이러한 접근은 uncoalesced access라 한다.
프로그래머는 scratch pad와 L1 data cache를 모두 효율적으로 사용하기 위해 bank conflict와 uncoalesced access를 모두 고려하며 프로그래밍해야한다.
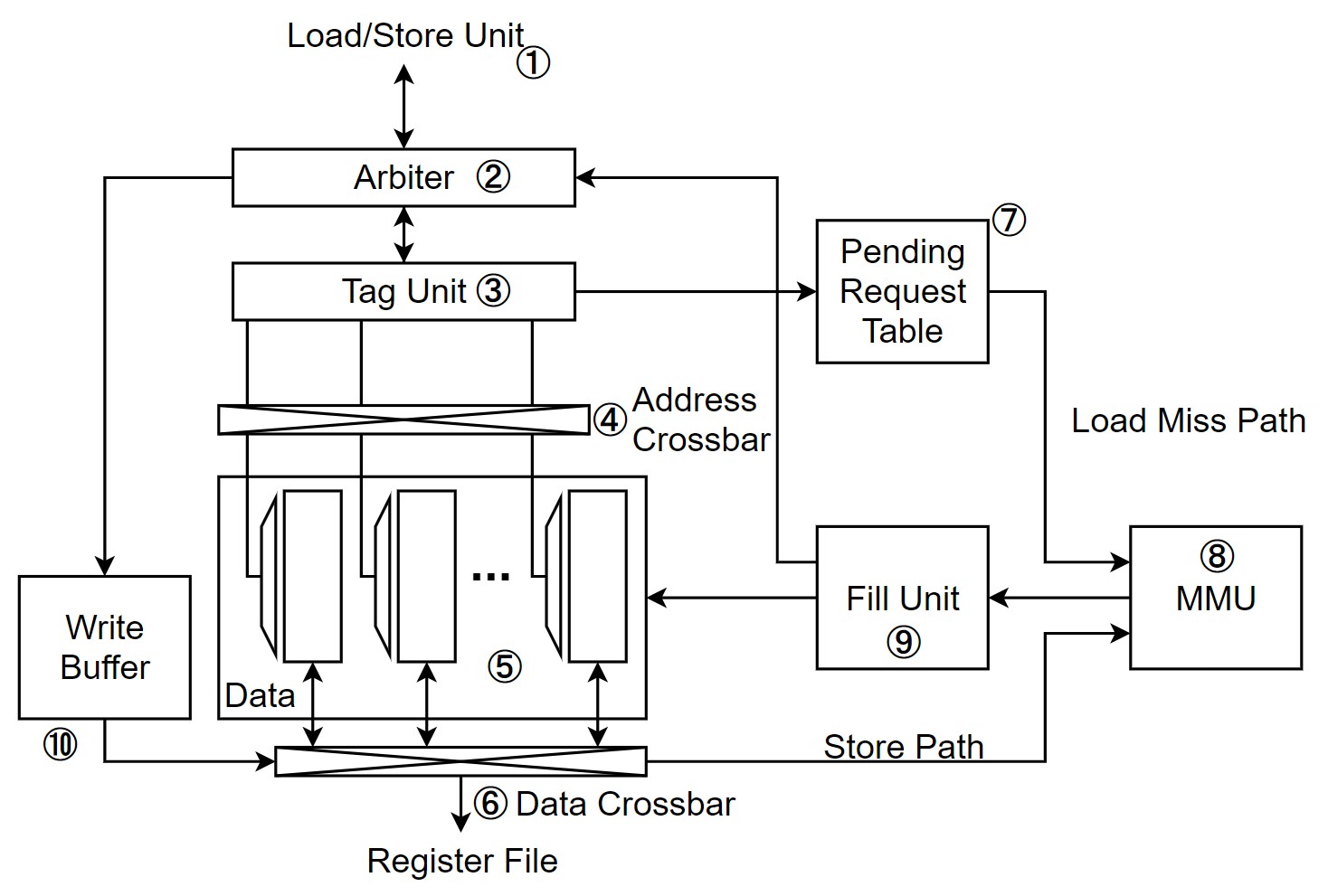 |
|---|
| Figure 1. Unified L1 data cache와 scratch pad 메모리 |
Figure 1.은 NVIDIA의 Fermi와 Kepler 마이크로 아키텍쳐에서 보여준 unified L1 cache의 구조이다. Unified L1 cache는 L1 data cache와 scratch pad가 동일한 SRAM data array ⑤를 사용하는 구조로, 일부는 scratch pad 메모리를 위해 direct mapped cache로 설정되어 있고 다른 일부는 set associative cache로 설정되어 있다. 해당 디자인은 instruction pipeline의 stall을 막기 위해 bank conflict와 L1 data cache miss 발생 시 replay mechanism을 활용한다. Replay mechanism은 뒤에서 자세히 설명하도록 하겠다.
먼저 자세한 동작을 설명하기 전에 모든 memory access request는 instruction pipeline의 Load/Store Unit ①으로 보내진다. Memory access request는 여러 개의 memory address의 집합으로 이뤄져 있는데, 각 address는 warp 내의 각각의 thread가 필요로 하는 데이터의 주소이다.
이제 순서대로, scratch pad access의 동작에 대해 먼저 설명하고, L1 data cache의 coalesced cache hit, cache miss, uncoalesced cache hit의 동작을 설명하겠다. 위 내용을 머릿 속에 잘 염두해둔 채 읽으면 동작을 이해하는데 도움이 될 것이다.
Scratch Pad Memory Access Operation
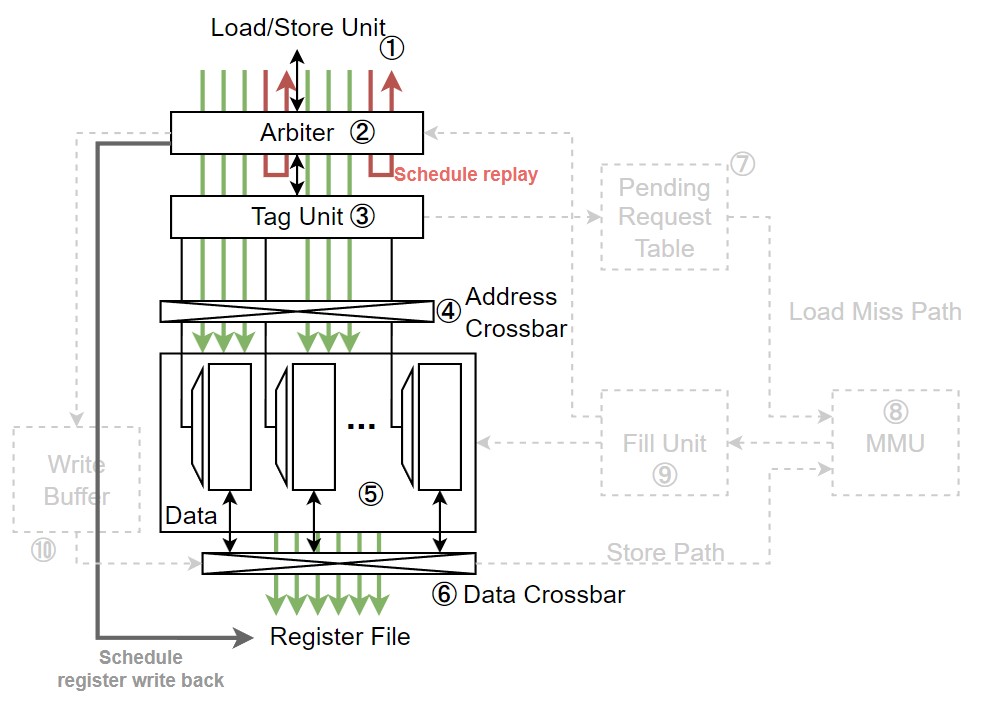 |
|---|
| Figure 2. Unified L1 cache에서 shared memory 접근 시 경로 |
- Shared memory 접근을 하게 되면, 가장 먼저 Arbiter ②가 해당 접근의 메모리 주소가 bank conflict를 일으키는지, 일으키지 않는지를 먼저 판단하게 된다.
- 만약 bank conflict를 일으킬 것 같다면, Arbiter ②는 request를 두 부분으로 나눈다.
첫 번째 부분은 bank conflict를 일으키지 않는 thread들이고, 나머지는 bank conflict를 일으키는 thread들이다.
Bank conflict를 일으키는 thread가 요청한 request는 다시 instruction pipeline으로 돌아가 다시 실행된다.
- 이러한 execution 방식을 replay라 부른다.
Replay는 area와 energy efficiency 사이의 trade-off가 존재한다.
Replay를 하게 되면, memory access instruction이 instruction buffer로 다시 돌려보내지기 때문에
area를 아낄 수 있지만, 큰 buffer를 다시 접근하기 때문에 energy를 소모하게 된다.
Instruction buffer의 buffering을 제한하는 것으로, 이를 해결할 수 있다. Buffer의 크기를 제한한 뒤, buffer의 남은 공간이 부족하면 memory access operation을 스케쥴링하지 않는다. 그러면 request가 나가지 않기 때문에, 버퍼를 사용하지 않는다. 덕분에 버퍼를 접근하지 않아 energy를 아낄 수 있고 buffer의 용량을 줄여 area도 아낄 수 있다.
- 이러한 execution 방식을 replay라 부른다.
Replay는 area와 energy efficiency 사이의 trade-off가 존재한다.
Replay를 하게 되면, memory access instruction이 instruction buffer로 다시 돌려보내지기 때문에
area를 아낄 수 있지만, 큰 buffer를 다시 접근하기 때문에 energy를 소모하게 된다.
- Bank conflict를 일으키지 않는 request들은 Tag Unit ③으로 전달된다. Shared memory는 direct-mapped cache이기 때문에 request는 Tag Unit ③을 lookup 하지 않는다.
- Arbiter ②가 request를 받아들임과 동시에 register file에 writeback을 미리 스케쥴한다. 왜냐하면 bank conflict가 발생하지 않는 상황에서 direct-mapped cache의 access latency는 일정하기 때문이다.
- Tag Unit ③은 Address Crossbar④를 제어한다.
Tag Unit ③을 lookup 하지는 않지만, 각 thread의 주소가 어느 bank에 맵핑되어 있는지 알기 때문에
Address Crossbar ④를 통해 reqeust가 Data Array ⑤를 올바르게 접근할 수 있게 해준다.
- Data Array ⑤는 32-bit 크기이며, 각 bank의 개별 row를 개별적으로 접근하더라도 처리할 수 있도록 decoder를 갖고 있다.
- Data Array ⑤를 통해 반환된 데이터는 Data Crossbar ⑥를 거쳐 올바른 thread lane의 register file로 쓰여지게 된다.
- 이때 active thread가 아니라면, register file에 쓰여지지 않고 무시된다.
- Shared memory 접근이 끝나면 replay를 실행한다. 만약 shared memory 접근에 1 cycle이 소모된다면, replay는 1 cycle 이후에 진행된다. Replay 된 request들은 다시 L1 cache의 Arbiter ②를 접근하며, bank conflict가 또 일어난다면, request는 다시 나뉘게 된다.
Cache Read Operations
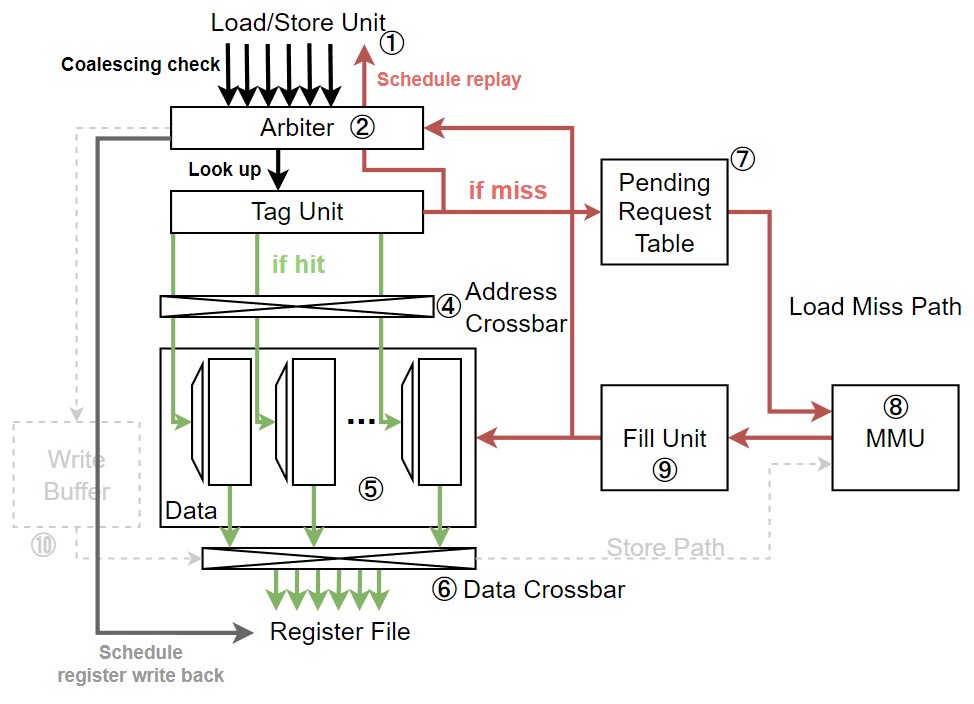 |
|---|
| Figure 3. Unified L1 cache에서 cache read 동작 시 경로 |
L1 cache의 Data Array ⑤는 많은 수의 bank로 이루어져 있기 때문에 개별 warp는 shared memory를 각각 접근할 수 있다. 반면, global memory 영역에 속하는 L1 memory는 1 cycle에 하나의 cache-line만 접근 가능하도록 제약이 걸려있다. 이 제약 덕분에 tag overhead를 줄일 수 있다.
Fermi와 Kepler micro-architecture에서는 128B cache-line 크기를 갖지만, Maxwell부터는 이를 4개로 나눈 32B cache-line 크기를 갖는다. 각각의 32B를 sector라 부르는데, 덕분에 낭비되는 GP-GPU의 대역폭을 아낄 수 있게 됐다. Sector의 크기를 32B로 둔 이유는, GP-GPU에서 사용하는 DRAM의 접근 크기 때문이다. GDDR5나 HBM2와 같은 GP-GPU 용 메모리 인터페이스 표준은 최소 접근 단위가 32B이다. Sector의 크기가 32B보다 더 작아도 DRAM은 무조건 32B로만 접근이 가능하기 때문에, 32B의 sector를 갖게 됐다.
이제 cache read 과정을 살펴보자.
- Load/Store Unit ①은 가장 먼저 request의 메모리 주소를 계산한 다음 coalescing 여부를 판단한다.
- 그 다음 coalesced request는 Arbiter ②로 전달된다.
- 이때 Arbiter ②는 request 처리 자원이 부족하다면 request 처리를 거부할 수 있다. 예를 들어, cache set의 모든 way가 처리 중이거나 Pending Request Table (PRT) ⑦의 공간이 없다면 request는 거부된다.
- Request miss를 처리할 자원이 충분하다면 Arbiter ②는 instruction pipeline의 register file에 writeback을 미리 스케쥴한다.
- Arbiter ②는 정해진 cycle 뒤에 cache hit이 일어날 것을 알기 때문에 미리 스케쥴을 할 수 있다.
- 이와 동시에 Arbiter ②는 Tag Unit ③의 lookup을 실시한다.
- Cache hit이라면, Data Array ⑤의 모든 bank에서 해당하는 row를 접근해 Data Crossbar ⑥를 거쳐 register file로 데이터를 반환한다.
- Shared memory 접근과 마찬가지로, active thread에 해당하는 thread lane만 업데이트 된다.
- Cache miss라면, Arbiter ②는 Load/Store Unit ①에 request를 replay 해야 한다고 전달한다.
그와 동시에, PRT ⑦에 request 정보를 전달한다.
- PRT ⑦는 CPU의 Miss-Status Holding Registers (MSHRs)와 비슷한 역할을 한다. 이는 miss request들이 in-order로 돌아올 수 있도록 관리하며, 동일한 miss request들은 하나로 합쳐 효율성을 높이는 역할도 수행한다.
- PRT ⑦는를 통과한 miss request들은 Memory Management Unit (MMU) ⑧로 전달된다. GP-GPU의 L1 cache는 virtually indexed & virtually tagged (VIVT)로 동작하기 때문에, MMU ⑧는 virtual to physical address translation을 거친 뒤, crossbar interconnect를 통해 적절한 memory partition unit 내부의 L2 cache bank로 request를 전달한다.
- Memory request가 모두 처리된 뒤, core에 전달되기 위해 돌아오면 MMU ⑧는 Fill Unit ⑨으로 request response를 넘긴다.
- Fill Unit ⑨은 request 내의 subid를 통해 PRT ⑦를 lookup 한 후, Arbiter ②에게 신호를 전한다.
- Arbiter ②는 이제 Data Array ⑤내에 request에 대한 데이터가 무조건 있기 때문에 cache hit이 발생할 것이란 걸 알고 Load/Store Unit ①을 다시 스케쥴한다.
Cache Write Operations
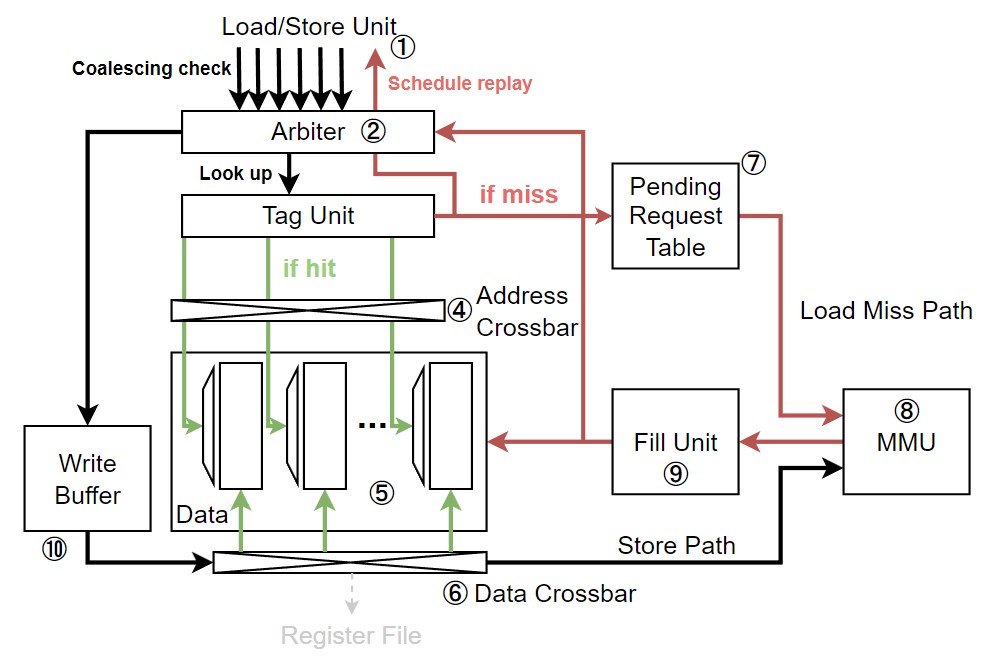 |
|---|
| Figure 4. Unified L1 cache에서 cache write 동작 시 경로 |
L1 data cache는 write through와 write back 정책을 모두 지원한다. 이는 memory space에 따라 결정 된다.
- Global memory: GP-GPU의 kernel은 종료 직전에 대량의 데이터를 메모리에 쓰기 때문에 temporal locality가 좋지 않을 것으로 예상할 수 있다. 따라서 write through with no write allocate 정책을 사용하는 것이 바람직하다.
- Local memory: Spilling register로 인해 local memory 영역에 데이터를 쓴다면 temporal locality가 좋을 것으로 예상할 수 있다. 따라서 write back with write allocate 정책을 사용하는 것이 바람직하다.
- Cache에 쓰여질 데이터는 shared memory든, global memory든 관계없이 Write Data Buffer (WDB) ⑩에 먼저 쓰여진다.
- 만약 쓰고자하는 block이 cache에 존재한다면, Data Crossbar ⑥를 통해 Data Array ⑤에 데이터를 쓰게 된다.
- Cache block이 존재하지 않는다면, L2 cache나 DRAM 메모리에서 block을 먼저 읽어온다.
위 과정 중에서 uncoalesced access나, 일부 thread가 마스킹 되어 있는 경우라면 cache block의 일부에만 데이터를 쓴다. Cache block의 모든 데이터를 써야하는 coalesced write인데 해당 block이 invalidate 상태라면, cache는 건너 뛰고 하위 메모리에 바로 write을 한다.
주의할 점으로는 NVIDIA GPU의 L1 data cache는 cache coherence를 지원하지 않는다. 따라서 여러 thread가 동일한 메모리 위치에 데이터를 쓸 때, 원치 않는 결과를 얻을 수도 있다.
정리
이번 포스트에서는 GPU의 L1 cache를 중심으로 설명했다. 이외에도 GPU 메모리 계층에는 L1 texture cache, L2 cache, memroy partition 등이 있다. 이들은 다음 포스트에서 다뤄보도록 하겠다.
참고 자료
- T. M. Aamodt, W. W. L. Fung, and T. G. Rogers, General-purpose graphics processor architectures. San Rafael, California: Morgan & Claypool Publishers, 2018. doi: 10.2200/S00848ED1V01Y201804CAC044.
Leave a comment