GP-GPU 구조 시리즈: 챕터 4-2 - Memory System
이번 포스트에서는 GPU의 L1 cache외의 메모리 계층인 L1 texture cache, L2 cache, memroy partition에 대해 다뤄볼 예정이다.
First-Level Memory Structures
이전 포스트에서 GPU의 first-level 메모리 계층에는 unified L1 data cache와 L1 texture cache가 있다고 소개했다.
Unified L1 data cache는 이전 포스트에서 다뤘으니, L1 texture cache에 대해 이야기해볼까 한다.
L1 Texture Cache
최근 NVIDIA의 GPU는 L1 data cache와 texture cache를 통합해 면적을 아끼는 방향으로 설계를 한다. 통합된 cache가 어떻게 동작하는지 알기 위해서, 이 챕터에서는 둘을 따로 떼어내 설명을 하고 있다. 이를 염두해두고 L1 texture cache에 대해 알아보도록 하자.
이 책에서는 GPU의 “general-purpose” 기능에 초점을 맞추고 있기 때문에, 그래픽만을 담당하는 가볍게 훑고 넘어갈 예정이다.
그 전에 3D graphics에 대해 알아볼 필요가 있다. 3D graphics을 컴퓨터로 구현하려면, 3D model을 만든 뒤 그 위에 texture를 입혀야 한다. 이 과정을 texture mapping이라 부르는데, texture mapping을 구현하기 위해서는 texture 이미지 중 일부 샘플의 좌표를 먼저 알아야한다. 이 샘플을 texel이라 부른다.
Texel을 메모리에 저장할 때, texel의 좌표를 메모리 주소로 활용한다. 왜냐하면 인접 texel들은 memory access 시에 함께 활용될 가능성이 높기 때문이다. 이러한 locality를 잘 활용한다면 cache의 효율을 높일 수 있다.
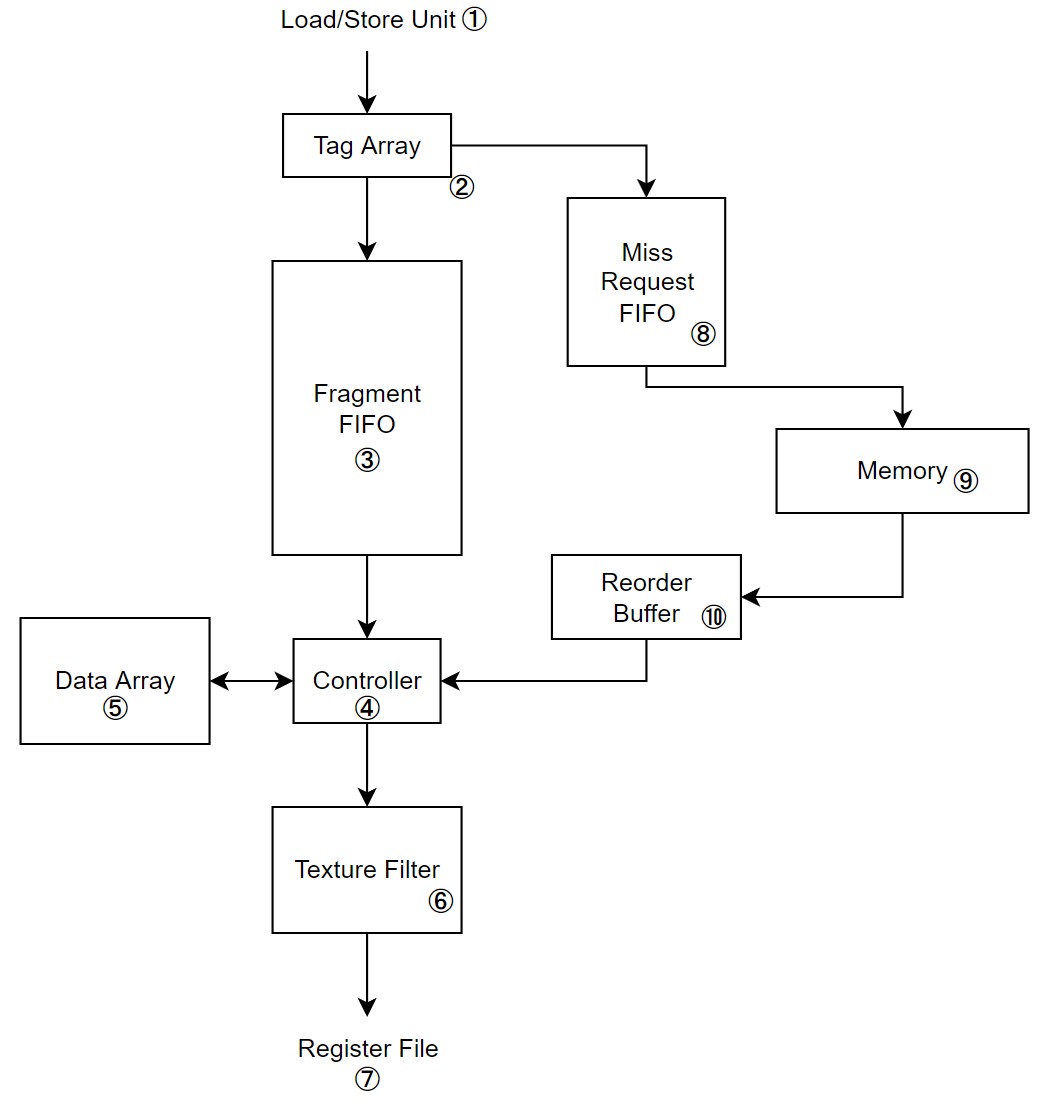 |
|---|
| Figure 1. L1 texture cache 구조 |
Figure 1.은 L1 texture cache의 구조이다. L1 data cache와 달리, tag array와 data array는 FIFO buffer ③에 의해 분리되어있다. 이는 DRAM에서 서비스 되는 miss reqeust의 latency를 숨기기 위함이다.
L1 texture cache는 FIFO로 인해 data array를 tag array보다 한참 뒤에 접근하게 된다. 이 시간은 대략 DRAM의 miss latency와 동일하다. FIFO를 이용해 miss latency와 hit latency를 비슷하게 맞췄기 때문에, throughput은 유지를 할 수 있게 됐다.
Unified Texture and Data Cache
이해를 돕기 위해, 여태까지 L1 data cache와 L1 texture cache를 분리해 설명했다. 하지만 실제로는 이 둘이 통합되어 있다.
그렇다 하더라도, 구조적 틀은 크게 변하지 않는다. Texture 값들의 경우 read-only 속성을 갖고 있기 때문에, 이를 통해 texture인지 아닌지 구분이 가능하다.
만약 read-only라면 texture cache의 FIFO buffer를 통해 data array를 접근하게 하고, 그렇지 않다면 address crossbar를 통해 data array를 접근하게 한다면, 여태 설명한 두 구조를 모두 간직하면서 통합을 시킬 수 있다.
On-Chip Interconnection Network
On-Chip interconnect는 GPU의 L1 cache와 L2 cache를 잇는 네트워크이다. 여기는 간단히 설명하고 넘어가겠다.
GPU의 높은 computational throughput을 감당하기 위해, GPU는 여러 개의 DRAM chip들은 각각 memory partition unit을 통해 병렬적으로 연결되어 있다. 또한 메모리 트래픽을 분산시키기 위해 memory partition unit 별로 address interleaving이 되어 있다.
그리고 GPU의 SIMT Core들은 on-chip interconnect를 통해 memory partition unit들과 연결되어 있다.
NVIDIA의 경우 crossbar 네트워크를 통해 on-chip interconnect를 구현했으며, AMD는 일부 제품에 한해 ring 네트워크로 구현되어 있다.
Memory Partition Unit
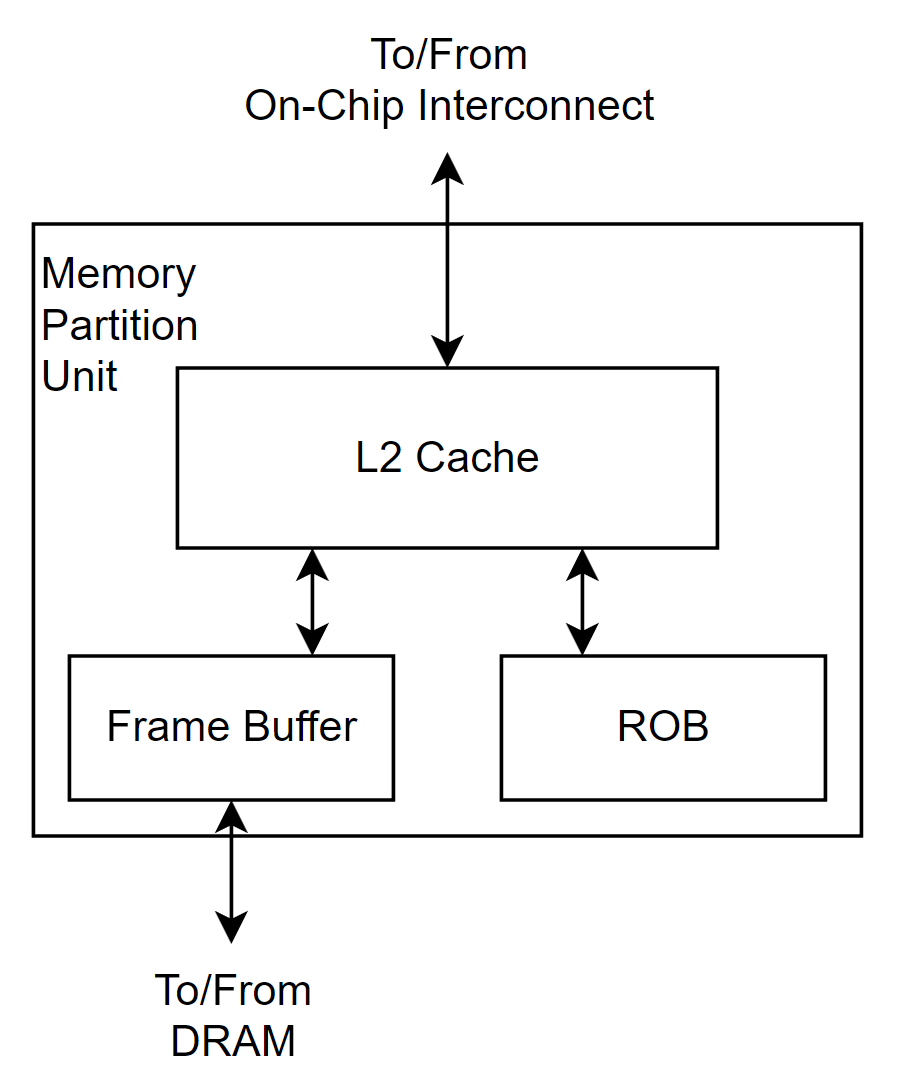 |
|---|
| Figure 2. Memory partition unit 구조 |
Memory partition unit은 L2 cache와 frame buffer라 불리는 memory access scheduler, 그리고 raster operation unit (ROP)으로 하드웨어이다. 대략적 구조는 Figure 2.에서 확인할 수 있다.
L2 cache는 graphics 데이터와 compute 데이터를 모두 저장하며, memory access scheduler는 DRAM read/write operation의 overhead를 줄이기 위한 역할을 한다. 그리고 ROP는 graphics 연산에 주로 사용되지만, atomic 연산 역시 담당한다.
L2 Cache
Memory partition unit 내에서 L2 cache는 두 개의 slice로 구분되어 있다. 각 slice는 개별적인 tag array와 data array를 가지며, 들어오는 request를 순차적 (in-order)로 처리한다.
GDDR5 DRAM의 최소 access 사이즈인 32-Byte에 맞추기 위해, L2 cache는 4개의 32-Byte sector로 구성되어 있다.
Coalesced write의 경우, throghput을 높이기 위해 write miss 발생 시, DRAM에서 데이터를 read 하지 않고 각 sector를 완전히 overwrite한다. 일반적인 CPU는 write miss 발생 시, DRAM에서 데이터를 읽은 후, 필요한 부분만 write하는 것과는 차이를 보인다.
Uncoalesced write은 문서에 나와있지 않아 정확히 어떤 식으로 동작하는지 알 수 없지만, 두 가지 방법이 존재할 것으로 추측할 수 있다. 하나는 byte-level valid bit을 두는 것이고, 다른 하나는 L2를 그냥 bypass하고 DRAM에 쓰는 것이다.
Memory access scheduler의 면적을 줄이기 위해, memory에 쓰일 데이터는 L2 cache에 버퍼링 되어 차례를 대기한다.
ROP
ROP의 경우, graphics 연산 뿐만아니라 atomic operation이나 reduction operation을 수행한다.
동일한 메모리 주소를 연속적으로 접근하는 atomic operation의 경우, local ROP cache를 이용해 pipeline을 한다.
Memory Access Scheduler
Memory partition unit은 여러 개의 memory access scheduler를 갖고 있다. 이들은 L2의 각 slice와 연결되어 off-chip DRAM의 접근을 돕는다.
모든 memory access scheduler는 read request와 write request를 정렬하기 위한 sorter를 각각 가지고 있으며, DRAM의 한 bank의 같은 row를 접근하는 여러 read request를 하나로 묶기 위해 2개의 테이블을 가지고 있다.
첫 번째 테이블은 read request sorter로, set associative cache이다. Read request sorter는 read request의 메모리 주소를 이용해 테이블을 접근하며, 여러 read request가 특정 bank 내의 하나의 row를 접근하려고 한다면 포인터를 이용해 해당 row를 가리킨다.
두 번째 테이블은 read request store로, 위에서 사용된 포인터를 이용해 테이블을 look-up하면 개별 read request가 어떤 것인지를 알려준다.
정리
여기까지가 NVIDIA GPU의 대략적인 구조이다. 이 책은 Volta architecture까지의 내용이다 보니, 최근 마이크로아키텍쳐인 Ampere나 Lovelace, Hopper와는 조금 다른 구조를 가지고 있을 수도 있다. 하지만 대략적인 구조는 비슷할 것으로 생각되기 때문에 GPU를 공부하면서 많은 도움이 될 것이라 생각한다.
책의 내용을 블로그에 정리를 해두긴 했지만 테크 블로그에 포스팅하는 것이 처음이다보니, 부족한 부분도 많고 두서 없는 내용들도 많다. 따라서 정확한 내용은 책을 직접 읽어보기를 권장한다.
오랜 기간에 걸쳐 시리즈를 작성했는데, 이해가 안되는 부분도 많고 글솜씨도 부족하다보니 많은 아쉬움이 남았다. 블로그를 자주 관리하지 못하다보니 게시글을 빨리 올려야된다는 생각이 들었고, 그래서 급하게 작성한 것도 없지 않다. 그러다보니 내가 공부한 것들을 쉽게 풀어서 정리했다는 느낌보다는 단순히 번역만 한 느낌이 됐는데, 언젠가 시간이 난다면 완벽히 이해한 다음 글들을 수정해야겠다.
참고 자료
- T. M. Aamodt, W. W. L. Fung, and T. G. Rogers, General-purpose graphics processor architectures. San Rafael, California: Morgan & Claypool Publishers, 2018. doi: 10.2200/S00848ED1V01Y201804CAC044.
Leave a comment